

Technical Insights
2025年08月18日
China's AI Develops Its First Native Memory: Non-Transformer Takes the Lead, Robot Dog Steals the Show at WAIC
分享
Original article by 新智元 AI Era
Published on July 26, 2025, 17:33 | Shanghai

Introduction by AI Era
Just now, this emerging Chinese company has rolled out another major update to its pioneering non-Transformer architecture large model! Its training efficiency significantly outperforms Transformer-based architectures, drawing massive attention at WAIC. The iPhone moment for edge AI has truly arrived.
Just now, at the WAIC (World Artificial Intelligence Conference), emerging Chinese AI company RockAI once again delivered plenty of excitement.
The latest version of its large model, Yan 2.0 Preview, was officially unveiled!
Learn and remember on the spot, guess which bottle is our favorite drink?
Not only can it run on multiple devices, such as robotic hands, robotic dogs, PCs, and tablets, but it can also be deployed with no loss of performance.
The model's autonomous learning ability and multimodal capabilities have left audiences truly amazed.
Native Memory
Learns After Just One Teaching, Responds Accurately
For example, the robotic dog in the video below initially didn't know how to greet people yet.
To teach it, the staff personally demonstrated the action, recorded a video and said, "This action is called saying hello."
After watching the video, the robotic dog, to everyone's surprise, instantly mastered the move!
The next command was for the robotic dog to fetch a bottle of drink. Since it had never been taught to do this, it again could not do it at first.
Then, simply by showing the bottle to the camera and saying, "This is my favorite drink," it instantly learned it.
Out of two bottles, it picked the correct one, which was truly impressive.
Even the robotic hand in the video below—which can see, hear, and reason—not only plays games autonomously but also understands human commands, instantly completing tasks such as grabbing gold in the Gold Mining game and pushing boxes in the game of Sokoban.
Note that this process not only requires the robotic hand to use the keyboard with extreme precision, but also requires it to use its “brain” to think and make accurate judgments.
Surprisingly, it did it with great accuracy!
These capabilities are something that even leading companies like OpenAI have yet to achieve, showing that RockAI is at the forefront of the industry.
Offline Intelligence
The Real Edge AI
Why is it said that the Yan architecture large model can achieve 100% offline deployment and become the real “edge AI”?
The answer lies in its groundbreaking underlying architecture.
Unlike most current models, Yan 2.0 Preview is based on RockAI's pioneering non-Transformer architecture.
It is not only extremely lightweight but also highly performant—with just 3B native parameters, it surpasses the Llama3 8B, which is larger in scale, in multiple key tests.
More importantly, its training efficiency far exceeds that of the Transformer architecture that dominates today's AI landscape.

Reportedly, an even bigger and more powerful 40B model is already on the way!
Now, following the successful official registration of the Yan 3B model, the Yan 2.0 Preview has brought two major capability breakthroughs.
The first is its continuous video understanding capability.
For example, when a person performs various continuous actions in front of the robotic dog, it can replicate them exactly, thanks to the model's video capabilities.
Yan 1.3 achieved understanding and processing of images and audio through multimodal expansion, while Yan 2.0 Preview further supports video, which practically means completing the final piece of the multimodal puzzle.
Therefore, Yan 2.0 can be said to achieve real multimodality: a single model can not only process text, but also images, audio, and video, while simultaneously generating text and audio end-to-end.

The second breakthrough is the innovative introduction of neural network-based memory units in 2.0, building on the 1.3 architecture.
Specifically, information storage, retrieval, and forgetting are realized through differentiable memory modules in the neural network’s parameter layer as “built-in memory.”

Yan 2.0 Preview architecture diagram
As shown in the figure above, forward propagation can be divided into two stages: memory update and memory retrieval.
Memory update is a dynamic adjustment: during forward propagation, it can retain long-term dependencies through gated updates and flexibly integrate new knowledge based on the characteristics of input distribution.

Unlike solutions such as “context engineering,” which explicitly store memory information, RockAI implicitly stores relevant information in the weights of its multi-layer neural network. Through the neural network's capabilities of multi-level abstraction and non-linear modeling, it achieves superior memory performance.
In principle, the difference between this memory mechanism and other memory mechanisms is like the difference between early machine learning and deep learning.
This memory mechanism differs from other remote large models that incorporate a pre-attached database via methods like RAG. It is important to note that the latter rely on external memory—the models themselves do not truly retain the information.
It can be said that Yan 2.0 Preview—which adopts a feature-state-driven memory mechanism—has preliminarily validated the effectiveness of the memory network.
A memory module is necessary because, for AI to "learn while speaking" like a human, it must have memory.
On the path of autonomous learning based on synchronized training and inference, RocKAI has taken a solid step forward.
This is vividly demonstrated both in the multimodal real-time human-machine interaction when the robotic hand is playing games, and in the synchronized training and inference of the robotic dog.
During this process, RockAI discovered that they are not alone: their approach is similar to the explorations of Silicon Valley giants.
Whether it's Google's Titan architecture or Meta's Chief Scientist LeCun, they all emphasize that memory modules must be introduced into the model, as AI's learning ability is approximately equal to its memory capability.


However, the difference this time is that RockAI is taking the lead.
Yan 2.0 Preview not only explored the potential for memory using non-attention mechanism, but also successfully validated LLM memory capabilities for the first time.
Next, we move on to the question: what does the innovation of the non-Transformer architecture bring to the Yan architecture large model?
It Can Truly Run On Consumer-Grade Hardware
Because of this architectural-level innovation, the Yan architecture large model no longer needs to rely on cloud computing and can run on consumer-grade hardware.
Thus, it can directly give every edge device a "soul."
It not only seamlessly adapts to end devices such as UAVs, robots, PCs, and mobile phones, but also enables the model's intelligence to undergo a brand-new upgrade.
Since no model pruning is required, edge devices retain greater integrity and sustainability.
In contrast, models based on the Transformer architecture are fundamentally unsuitable for running on edge devices and performing autonomous learning.
This is because these models are typically quantized, pruned, and compressed before being deployed on edge devices. Once pruned, they lose their ability to learn.
The Yan architecture large model, however, avoids this shortcoming.
Across various small edge devices, the Yan architecture large model consistently performs exceptionally well.
On mobile devices, the Yan architecture large model is widely compatible with chips from Qualcomm, MediaTek, and others. It can run on CPUs without compression, pruning, or quantization, while requiring only 8GB of RAM and delivering outstanding performance.
On the Xiaomi 13, it can output at least 18 tokens per second; on the Redmi K50, at least 12 tokens per second; and on the T-phone, 7-8 tokens per second.

On robotic devices, the Yan model is already widely compatible with chips from Intel, Raspberry Pi, NVIDIA, and others.
With just 8GB of RAM, the Yan architecture enables robot running on an Intel i7-1255U to see, hear, speak, think, and move!

Why are they so determined to refine their technology to such a high degree of precision? The answer lies in their unwavering belief in "edge AI"—Make Every Device Its Own Intelligence.
Only by equipping every device with a brain can AI truly be accessible to everyone. Only when it can be used in third-, fourth-, and fifth-tier cities, and by both the elderly and children, can edge devices be considered truly accessible in practice.
Speaking of which, how did RockAI decide not to follow the mainstream Transformer path? Here is the story behind it.
Non-Transformer Architecture: Taking the First Step
In recent years, both academia and industry have gradually realized that everyone may have been overly influenced by OpenAI: attention mechanisms are not omnipotent, and Transformers have many flaws, such as their high complexity and computational demands.
The earliest skepticism came from OpenAI's Ilya: "If publicly available internet data runs out, how will GPT pre-training continue?"
Additionally, Logan Kilpatrick, product lead for Google Gemini, pointed out the biggest flaw of the current attention mechanisms in a recently published roadmap:
With the current attention mechanisms and context processing methods, it is impossible to achieve infinite context.
We need comprehensive innovation at the architectural core to achieve this goal.

At the same time, Google has been exploring Gemini Diffusion, a non-autoregressive model.
In addition, CMU's Albert Gu proposed the Mamba architecture in 2023, advocating the use of State Space Models for sequence modeling.
Recently, he strongly criticized the limitations of Transformer models, saying that the concept of "tokens" is meaningless.

In 2024, Karpathy, the father of “vibe coding,” also pointed out several issues with “tokenization.”

It can be said that, in some cases, Transformers are by no means the first choice, and attention mechanisms are by no means a strict rule!
What Does It Mean When Large Models Have Native Memory?
Memory Is No Longer An Add-On
In traditional large model architectures, knowledge and information often rely on external add-ons.
Whether through RAG to supplement knowledge, external databases for temporary user data storage, or search engines, such solutions resemble a “patchwork intelligence”—powerful but lacking continuity.
Today, RockAI is embedding memory capabilities directly into the model itself. It is no longer an external module, but an integral part of the model—even its core.
For example, the robotic dog they demonstrated can now exhibit “memory” of its environment, people's preferences, and past experiences through continuous interaction, behaving more like a living being. This indicates that AI is beginning to truly “remember” you.
From Interaction to Understanding: The Leap to Personalization
With native memory, large models are no longer just tools that “answer your questions next time”; they begin to understand you.
They can remember your preferred language style, personal preferences, and past decision-making habits. They can even provide more appropriate suggestions for you through long-term observation, even when you haven't explicitly stated them.
Native memory capabilities not only make AI more “personalized” but also fundamentally transform the human-machine relationship.
It is no longer a relationship between a tool and an operator, but more like that between partners and collaborators. You no longer need to start from scratch each time; the AI gradually becomes an extension of your thinking.
Offline Deployment: A Win-Win for Privacy and Speed
More importantly, “large models with memory” do not rely on the cloud; they are deployed offline, with all memory taking place locally on your device—resulting in faster response times, lower latency, and stronger data security.
In today's world, where privacy is increasingly important, large models must deliver intelligence while protecting privacy to truly integrate into users' daily lives and influence personal decision-making.
The “edge device + memory” model may well be the key solution to this challenge.
The Underlying Mechanisms of Human Intelligence: Large Models Are Beginning to Possess Them Too
The evolution of human intelligence has always been inseparable from memory. Without memory, one cannot understand context, learn from experience, or develop personality. Now, large models are finally beginning to approach this fundamental essence of cognition.
RockAI's path of innovation has been relatively “lonely” in China—from its non-Transformer architecture design to its end-device memory capabilities, and its proposal to advance toward Artificial General Intelligence through collective intelligence. It seems that RockAI has become a solitary trailblazer of innovation.
A Lonely Pioneer Or The First to Take the Plunge?
At the end of the interview, AI Era asked RockAI's co-founder a bold question: What new forms will future edge AI devices take in a few years?
In 2007, Steve Jobs stood on stage, pulled out this small phone, and made the world buzz.

Since then, the iPhone 4 has transformed how humans use tools and expanded human senses.
However, the creation of the iPhone 4 relied on four key factors: a novel touch-based interaction method, the timely maturation of the ARM architecture, the iOS operating system, and the explosive growth of the app ecosystem driven by the App Store.
Today, some major Silicon Valley companies are betting on AI glasses, some on brain-computer interfaces, while Rock AI is betting on chips and operating systems.
They believe that, in the AI era, operating systems will inevitably incorporate AI model layers to make devices smarter.
The Yan large model—which can run offline, has extremely low power consumption, and is multimodal—is their first ace in the hole.
If the ultimate goal of “building an AI-era operating system” is achieved, devices like phones, tablets, refrigerators, and TVs will truly “develop a brain of their own.”
Looking around, electronic devices are everywhere—from refrigerators to computers; the total number of devices worldwide far exceeds the global population.
If every device were equipped with AI, how vast would the market be?
Currently, RockAI's 3B multimodal model can cover 70% of scenarios. Common functions like translation and meeting minutes can already be handled by the local Yan architecture large model.
RockAI already has many partners with strong collaboration intentions, such as chip manufacturers and audio-visual companies.
The next "iPhone moment" may be just around the corner. If every device can run AI offline, we will see this vision of the future become reality—achieving the true vision of “everything has a soul.”
推荐新闻
-


Harnessing Collective Intelligence Instead of Creating Gods: This Company Takes a Unique AGI Path Different from OpenAI
-

LLM Architecture Design and Algorithm Optimization for Edge AI
-

RockAI Participated in the Hong Kong EFAE with Its Partner, Where Autonomous Learning and AIPC Attracted Great Attention!
-
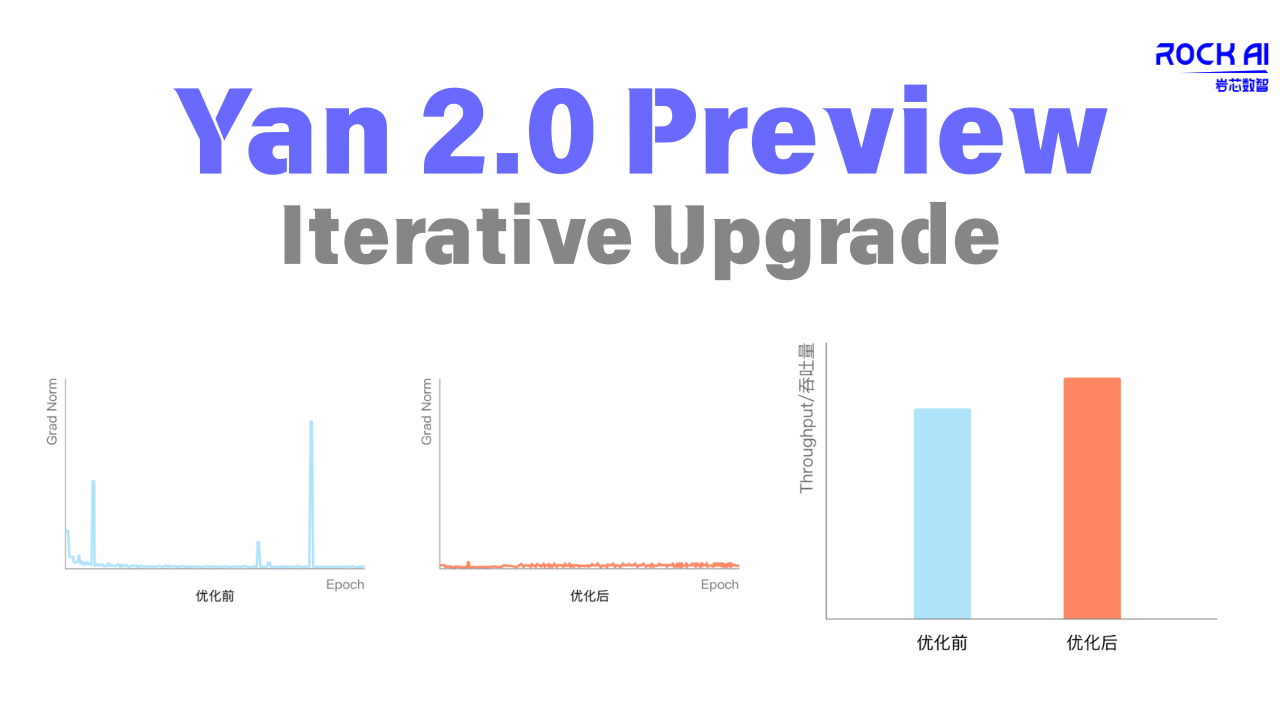
Yan 2.0 Preview Iterative Upgrade: More Stable Training, Faster Inference









