

Technical Insights
2025年08月15日
The King of Non-Transformer Architecture Deployment Emerges at WAIC with Offline Intelligence and Native Memory
分享
Original Article by Hengyu, Xinyi | Quantum Bit
Published on July 26, 2025, 14:34 | Shanghai
WeChat Official Account :QbitAI
Just now, at a WAIC exhibition booth, a robotic dog—completely offline—learned a brand-new trick.
A middle-aged visitor taught it live: first spin, then stand upright and perform the classic “puppy wave.”
Within two minutes, the dog replicated the sequence exactly—no preset program, no remote control, fully offline.

Nearby, several robotic hands alternated between playing Gold Miner and Sokoban with impressive skill.
According to booth staff, these hands were also operating entirely offline, driven purely by on-device vision models—capable of understanding scenes and executing strategies locally.
Robotic hands, robotic dogs, and other humanoid devices were among the main crowd-pullers at this year’s WAIC.
The reason for sharing this observation is twofold. One is both devices performed remarkably well in true offline mode. Another one is the models powering them are large-scale models based on a non-Transformer architecture.
A booth representative explained that the underlying intelligence is native to the device—capable of running offline, supporting multimodality, and learnsynchronously.
Behind this system is RockAI, a two-year-old company.
Even before ChatGPT’s global breakthrough, RockAI began in early 2022 to fully commit to non-Transformer large models, rebuilding AI’s operational logic from the ground up.
During WAIC, RockAI founder Liu Fanping publicly stated:
“AI must overcome two mountains—backpropagation and Transformer.”
When Large Models Possess Native Memory Capability
At the RockAI booth, both the self-learning robotic dog and the game-playing robotic hand ran the Yan 2.0 Preview large model.
Compared to Yan 1.0’s language abilities and Yan 1.3’s multimodal understanding, the breakthrough in 2.0 Preview is memory—specifically, a native memory module.
This memory is not constrained by fixed-length context windows. Yan 2.0 Preview can learn continuously—adapting and evolving with use.
Nowadays, when using large models, people often encounter this situation: if a question falls outside the chatbot’s training data coverage, the response is either, “I’m sorry, my knowledge only goes up to [month] 2024, and I cannot provide relevant information,” or a completely fabricated answer—frustrating enough to make one pull their hair out.
This stems from the conventional large-model paradigm of “train first → then deploy → no updates during use.”
As a result, online search has become almost a standard feature for chatbots.

However, compared to native memory, solutions such as online search, external memory banks, and extended context windows do not truly address the core problem.
To tackle this, Yan 2.0 Preview introduces a new mechanism called train-inference synchronization.
Train-inference synchronization means the model is no longer a static, frozen product, but a continuously evolving intelligent agent. Every interaction with the environment and every new task scenario becomes nourishment for the model’s autonomous learning and evolution.
To explain how this continuous learning capability is achieved, we must look at RockAI’s memory module design for Yan 2.0 Preview.
Its forward process can be divided into two stages: memory update and memory retrieval.

Let’s start with the memory update phase.
In this phase, the model determines which outdated knowledge can be forgotten, then extracts valuable information from the current task and writes it into the memory module.
This process relies neither on external plugins nor on caching. Instead, a dedicated neural network simulates memory behavior to dynamically erase and incrementally write information—retaining critical historical data while flexibly integrating new knowledge.
Next comes the memory retrieval phase.
Yan 2.0 Preview employs a sparse memory activation mechanism, selecting the Top-K active memory slots from multiple memory banks, merging them with long-term shared memory, and generating new outputs.
This enables the model not only to have a memory, but also to reason with memory.
Combined, these mechanisms allow Yan 2.0 Preview to achieve an initial validation of memory network effectiveness—transforming the model from a static brain into a growing intelligent agent.
In RockAI’s words, this marks a major step toward autonomous learning based on train-inference synchronization.
Although fully realizing autonomous learning based on train-inference synchronization may still be impossible today, the idea stems from a highly pragmatic starting point.
As early as 2022, at its inception, RockAI completely abandoned the Transformer architecture, choosing a fundamentally different path at the AI infrastructure level.
The reason was simple—
RockAI focuses on serving edge-side applications, whereas Transformer-based models, despite their strong performance in language tasks, consume massive computational resources and memory, and are extremely compute-intensive during inference.
In particular, for long-sequence inputs, the self-attention mechanism in Transformers incurs quadratic complexity in both computation and memory, making it a natural bottleneck in edge deployment scenarios.
For typical edge environments such as smartphones, robots, and IoT devices, resource sensitivity is the norm—not the exception.
At that time, RockAI concluded:
For AI to truly become basic infrastructure, it must be deeply integrated with specific devices. Only when AI can run efficiently on every terminal device can it truly permeate every aspect of human life.
Following this philosophy, the Yan architecture was created, evolving through versions 1.0 and 1.3, leading to today’s Yan 2.0 Preview.

It is important to note that Yan 2.0 Preview is not a complete product release; its significance lies more in serving as a key technical rehearsal for RockAI.
What they aim to validate this time is not whether the model can answer questions or generate text and images, but a more fundamental question:
Can an AI model, like a human, learn through use and grow smarter over time?
The importance of this question goes far beyond the technology itself. If the answer is yes, our understanding of AI must change—it would no longer be merely a tool, but an intelligent partner capable of active growth.
An autonomous learning mechanism based on train-inference synchronization stores useful information implicitly within the weights of multilayer neural networks—an approach more elegant than explicit context engineering and more closely aligned with how the human brain operates.
Therefore, the robotic hands playing games and the self-learning robotic dog at the booth should not be seen simply as exhibition entertainment. At a deeper level, they serve as a preview of what’s possible—that AI may be on the verge of entering an entirely new stage of evolution.
Offline Intelligence Enables Models to Be Born and Grow Directly on Devices
The path toward AGI is still under exploration, but the direction is clear: simpler algorithms, lower compute dependence, and reduced data requirements.
RockAI states that to truly move AI into this evolutionary stage, simply bolting on external features is not enough. The change must begin at the underlying architecture level, addressing the systemic issues that hinder AI’s ability to take root and grow.
“Transformer-based models were destined from the start to be unsuitable for running on edge devices,” said RockAI CTO Yang Hua.
Does that sound like a bit of a provocative statement?
In reality, it is far from baseless.
Since ChatGPT’s explosive debut, Transformer-based models have swept the industry, scaling ever higher and proving effective countless times worldwide.
However, it is well known that due to the Transformer architecture’s inherent computational design, it can be cumbersome in many scenarios.
For example, in the current surge of interest in inference models, once a Transformer model enters the inference phase, its complexity grows dramatically with input sequence length. Every additional token requires recalculating attention relationships across the entire context.
In other words, even if you compress a large model as much as possible, as long as it remains Transformer-based, longer contexts and higher task complexity will significantly slow inference speed while driving power consumption sharply upward.
As a result, on compute-constrained devices such as smartphones, robots, and IoT terminals, Transformer-based models are at a disadvantage.
Addressing the current predicament, the industry today, the main approaches are either edge–cloud collaboration or putting cloud models on a strict “diet”—compressing them again and again to squeeze them into edge devices.
In essence, these mainstream methods still apply cloud-centric thinking to serve edge-side realities.
RockAI takes a different path.
Instead of adapting models to fit devices, the company enables models to be born and grow directly on the device itself.
The previously mentioned Yan architecture was designed specifically for the edge. RockAI’s goal is to make the model an integral part of the device—a concept the company calls Offline Intelligence.
Offline Intelligence is not simply running without internet. It is a full-cycle, closed-loop system that performs understanding, reasoning, and even learning locally.
Its core features are:
1.Full Local Execution
Inference does not rely on cloud computing. The model is deployed on the device and remains usable offline.
2.Multimodal Understanding
Capable of processing complex inputs such as voice, images, and video, with strong local perception and interaction abilities. Currently, Yan 2.0 Preview can perform multimodal Q&A on a Raspberry Pi at 5 tokens per second.
3.Continual Learning Through Usage
With training–inference synchronization, new information from user interactions can be written into the local model’s memory, enabling gradual growth.
This breakdown highlights what makes offline intelligence truly different—
Traditional AI connects to a brain in the cloud. Edge–cloud collaboration asks the cloud when in doubt. Offline Intelligence relies solely on the brain it already has—understanding, learning, and responding autonomously.
RockAI emphasizes that an edge large model should not be a shrunken copy of a cloud model. Instead, it should be an innovative architecture designed for private, local deployment on devices. Its core lies in multimodal perception–based autonomous learning and memory, enabling personalized services while safeguarding data privacy and operational security.
In essence, RockAI envisions this as the true brain of future terminal devices.
Memory will be vital for these devices, enabling them to genuinely understand and accompany users.
A large model with memory can continuously learn a user’s habits, environment, and emotions, providing more precise, personalized services while protecting privacy.
Humans spend a lifetime growing through memory. Future devices will likewise build their own experiences through memory—becoming warmer, more discerning, and capable of intelligent companionship.
From this perspective, RockAI’s vision goes beyond expanding model capabilities. With its Yan architecture, the company is betting on making memory a native capability of future on-device models.
China’s King of Non-Transformer Model Deployment
More importantly, the Yan architecture is far from a mere paper-concept reconstruction experiment—it has already taken root in real devices and started running in the wild.
According to official information, without pruning or quantization, the Yan-architecture large model series has successfully run on Raspberry Pi, Snapdragon 6-series mobile chips, AMD and Intel PC processors, and even robot main-control chips.

And it’s not just running in technical demos—it has also started real commercial deployment.
RockAI revealed that an AI PC, co-developed with a certain going global brand, will enter mass production and launch in the global market in the second half of this year. Meanwhile, other terminal devices developed in collaboration with various brands are steadily moving into the deployment phase.
Globally, RockAI is among the very few companies capable of achieving both a fully non-Transformer architecture and true on-device deployment.
In just over two years, they have taken one of the most unconventional routes to build a complete end-to-end deployment loop—earning the title of China’s king of non-Transformer model deployment.
But their ambitions go far beyond simply bringing offline intelligence to market.
RockAI’s brain-like activation mechanism, native memory capability, and pure offline deployment are not isolated features—they are three foundational pillars pointing toward a much farther destination: Collective Intelligence.
RockAI believes that collective intelligence is one of the key pathways toward AGI.
In human society, individuals have their own expertise, and collaboration creates power. RockAI envisions intelligent devices working the same way—where models collaborate through neuron migration or task-capability synchronization, forming an organized, specialized, and feedback-driven ecosystem of models.
In other words, RockAI’s vision for AI’s future is not a single, monolithic, hyper-centralized model, but countless interconnected “small brains” across devices—learning, evolving, and advancing together.

This seemingly radical approach is, in fact, increasingly echoed by emerging technological trends.
As demand for efficiency-sensitive scenarios has risen since last year, Transformer-based models have attracted growing attention and adoption from leading tech companies both domestically and abroad.
Even at the birthplace of Transformers—Google—a few days ago, a new underlying architecture, Mixture-of-Recursions (MoR), was released, halving memory usage and doubling inference speed. Many online commentators have jokingly called it a Transformer Killer.

Clearly, the industry is collectively asking: Has the Transformer architecture reached a crossroads?
For RockAI, the answer is yes. The surge of hybrid architectures reflects the industry’s subconscious acknowledgment that the original path is no longer sufficient.
Transformers continue to accelerate along their original track, but non-Transformer architectures are rapidly catching up. The difference is that the former speeds up on the existing rail, while the latter is forging an entirely new railway.
This path is challenging.
It requires circumventing the technical inertia of the entire AI ecosystem, and building out new toolchains, communities, and knowledge bases for the new architecture.
It is also a lonely road.
Currently, most mainstream models, hardware interfaces, and training paradigms worldwide are designed around the Transformer architecture.
Precisely for this reason, non-Transformer architectures deserve serious consideration. Before ChatGPT emerged, GPT itself appeared somewhat overshadowed by the brilliance of T5 and BERT.
RockAI believes that as long as this path solves real-world problems, it has intrinsic value.
If we shift our perspective from “who released a new version this week” or “the next benchmark leaderboard” to a ten- or even thirty-year horizon, perhaps the light that will truly illuminate the AI battlefield of edge–cloud competition and architectural debate will not be the loudest one today.
It may instead be a small spark that, once recognized as a starting point in the future, ignites a lasting flame.
推荐新闻
-


Harnessing Collective Intelligence Instead of Creating Gods: This Company Takes a Unique AGI Path Different from OpenAI
-

LLM Architecture Design and Algorithm Optimization for Edge AI
-

RockAI Participated in the Hong Kong EFAE with Its Partner, Where Autonomous Learning and AIPC Attracted Great Attention!
-
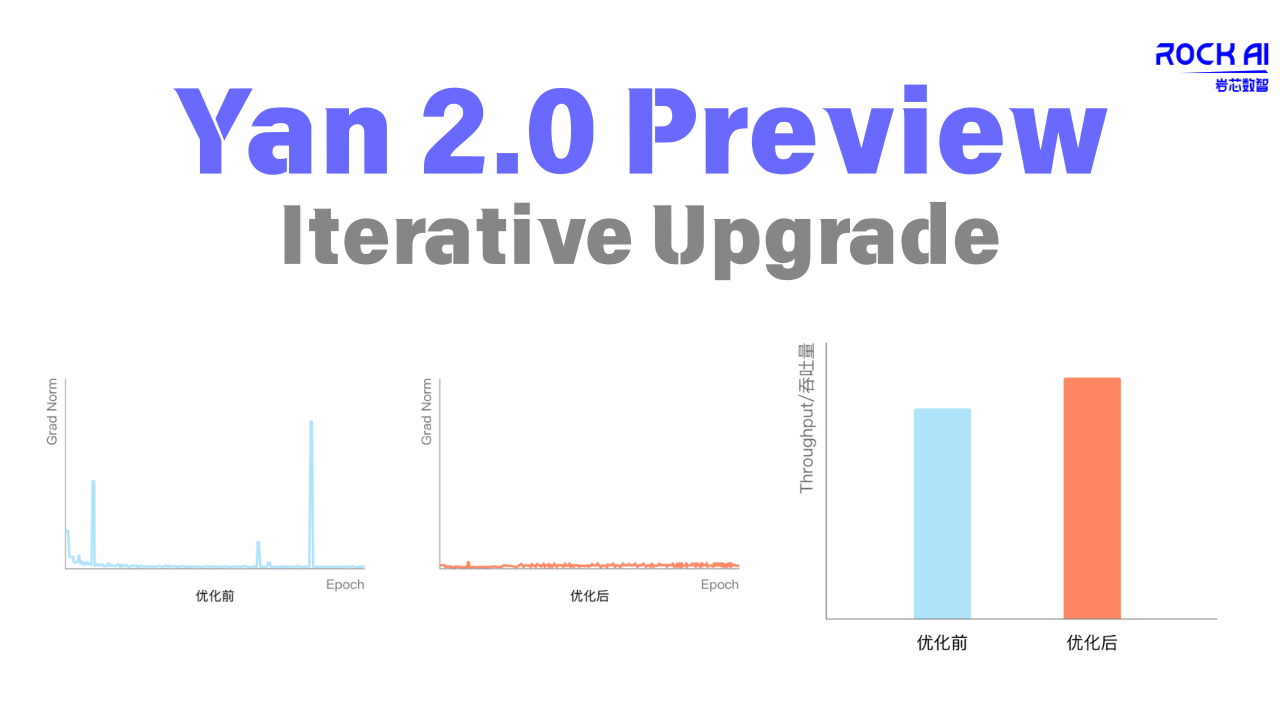
Yan 2.0 Preview Iterative Upgrade: More Stable Training, Faster Inference









