

Technical Insights
2025年08月25日
Offline Intelligence – When Will It Have Its "DeepSeek" Moment?
分享
Original article by 极客公园 GeekPark
Author: Li Yuan
Editor: Zheng Xuan
Published on July 26, 2025, 14:31 | Beijing

Real offline intelligence not only execute commands, but also continuously learns about you as you use it.
Over the past two years, the stories about AI models have largely centered around two versions: the omnipotent cloud and the imaginative edge.
In the past, a widely depicted industry blueprint was that as lightweight models continued to improve, it seemed only a matter of time before AI would break free from the constraints of the cloud and become an always-online, personalized intelligence on everyone's devices.
However, after the buzz faded, an uncomfortable reality came into view: whether it's the recently popular AI toys or the much-anticipated AI glasses, their core interactions and intelligence remain firmly tied to the cloud. Even with more powerful smartphones and PCs, those that have truly achieved offline AI capabilities remain few and far between.
In technical demonstrations, edge models appear capable of anything. Yet why does the so-called offline intelligence still end up depending on a network connection?
On one side is users' intense demand for the ultimate experience: instant responses without delay, no transmission of private data, and remain connected even when offline. On the other side, edge devices are forever constrained by their "physical limitations"—limited computing power, energy, and memory—which act like an invisible wall, harshly constraining the deployment of most high-performance models.
A deeper contradiction lies in the pull of commerce. For giants holding the most powerful models, the cloud is not only a benchmark for showcasing technological leadership, but also a lucrative profit gateway. When all attention and resources are focused on the cloud, the edge—more challenging, more labor-intensive, and offers less clear commercial returns—naturally becomes the overlooked frontier.
So, what are the few companies truly committed to advancing "offline intelligence" actually doing? At this year's World Artificial Intelligence Conference (WAIC), a company named RockAI gave its answer. They are walking a path few have taken and have found the key to breaking through.

With the mission to "make every device its own intelligence," this team dove headfirst into underlying technologies, even boldly abandoning the mainstream Transformer architecture to tackle the seemingly "impossible task" of edge deployment. Early on, their model could run seamlessly on the Raspberry Pi, a device with limited computational power—this card-sized computer has long been a rigorous evaluation standard for edge deployment, and most similar models often stall after running just a few sentences on it.
This year, the Yan 2.0 Preview, released at WAIC, with just 3 billion parameters, already supports multimodal capabilities and achieves true "memory" on the device: the model can dynamically adjust weights, and also retain and update user preferences over the long term.
The results of this "impossible task" have not remained confined to laboratory demonstrations. Mass production orders have already come in from both domestic and international markets, swiftly translating technical prowess into commercial value.
Their story may answer the fundamental question: When cloud-based models are advancing rapidly, why do we still need—and how can we achieve—true offline intelligence?
GeekPark interviewed RockAI's co-founder Zou Jiasi, discussing the commercial story behind RockAI.
01
Why Haven't We Have An AI That Will Always Be Available?
Q: The entire industry seems to be striving toward a future of offline intelligence, with giants like Apple viewing this as a core strategy. But why does the "last mile" from technical demonstrations to consumers' hands always seem so hard to accomplish?
Zou Jiasi: Everyone is talking about offline intelligence and AI on devices, but between the ideal and reality stand two nearly insurmountable obstacles: one is computing power, and the other is power consumption.
Large models require high computational power to run on devices. Currently, many AI companies in the industry have models with smaller parameters, but they still need more powerful chips to run them.
For example, one of our clients wanted to deploy an offline large model on a smartphone, but the solutions proposed by other large model manufacturers in the industry almost universally required the use of Qualcomm's latest flagship chip and at least 16 GB of storage. However, the reality is that most smart devices cannot support such high-performance chips.
This highlights the brutal divide in computing power: no matter how advanced your AI technology is, if it can only be applied to a few high-end devices, it misses the point of inclusive AI.
Another major obstacle is power consumption.
This issue is most evident in smartphones. In reality, whenever smartphone manufacturers attempt to deploy large models, the devices overheat significantly—a common problem with transformer-based architecture models. Almost all major smartphone manufacturers have discussed this pain point with us. They all aim to achieve breakthroughs in the next generation of AI smartphones, but face a barrier of power consumption.
Why is the final stretch so difficult to achieve?
The reality is that hardware updates occur at a slow pace. Many devices were sold years ago, and the chips, storage, microphones, and cameras from that time were not designed for today's large models. Deploying Transformers on mid-to-low-end computational power either results in failure or poor performance.
Even if upstream manufacturers release new high-end chips, integrating them into new product lines typically takes 6–12 months; and for the product to truly achieve commercial success, scale up production, and achieve widespread adoption usually requires an additional 1–2 years. This timeline is a reality that cannot be bypassed.
Q: You mentioned earlier that many problems stem from the current mainstream Transformer architecture, whether it be computing power or energy consumption. The Transformer has proven itself to be the strongest AI architecture in the cloud, so why does it struggle when deployed on edge devices?
Zou Jiasi: This question indeed hits the core of the major challenges in running AI models on edge devices. The Transformer's power stems from its revolutionary attention mechanism. However, the problem lies precisely here.
Traditional AI models operate like assembly line workers, processing information sequentially one by one, with limited memory, forgetting earlier information as they progress. The Transformer, on the other hand, acts like a super-powered commander. It doesn't process information sequentially but instead arranges it into a matrix, requiring every word in that matrix to "shake hands" with every other word once to calculate their mutual relevance.
This "global handshake" capability gives the Transformer extraordinary understanding ability. However, in the cloud, you have unlimited computational power to support such calculations.
But mobile chips (CPUs/NPUs) are designed more like the "assembly line workers" mentioned earlier—optimized at high-speed, sequential task execution. If you suddenly ask it to perform a task requiring this kind of "global handshake"—where each added character causes the computational load to surge dramatically—it instantly becomes overwhelmed.
We have been aware of this issue from the very beginning. The industry has also proposed some for improvements, such as Flash Attention and Linear Attention. However, our conclusion is that these are merely minor adjustments within the "command center" and do not fundamentally change the energy-intensive "global handshake" model.
We ultimately chose a more decisive approach: retaining the Transformer's strength in feature extraction while completely removing the energy-intensive Attention mechanism and replacing it with a brand-new architecture better suited for "assembly-line" execution. Around the same time, the Mamba architecture abroad also noticed a similar direction. We are not trying to patch up an F1 race car unsuitable for narrow roads but rather redesigning an off-road vehicle that can zip along narrow roads at high speeds.

Q: This sounds very complicated. Just to run on smart hardware, you have to redesign the architecture. Is offline intelligence really that necessary?
Zou Jiasi: That is an interesting question, and we believe it is absolutely necessary. We have also observed strong market demand for it.
Its necessity is relected in several benefits that cannot be replaced by the cloud:
First, absolute privacy and security. This is the fundamental aspiration behind companies like Apple investing in edge computing. The most sensitive data, such as your photo albums, health information, and chat logs, should never leave your device. This is a matter of principle.
Second, ultimate real-time interaction. Many scenarios require millisecond-level latency. For example, in drones deployed with the Yan architecture, when a user commands, "Capture a photo when I jump," the model must respond instantly. In such scenarios, even a single network instability could be critical, so relying on the cloud is not an option. Another example is future robots, which need to perform precise movements based on their unique arm length and sensor parameters. This real-time control, tightly coupled with the hardware, must be executed locally by the device's "brain."
Third, cost considerations. While cloud API prices appear to be declining, even to the point of being free, they still incur costs. Take cameras as an example, where shipment volumes are measured in the hundreds of millions. At such massive scales, multiplying even cheap cloud services by hundreds of millions leads to astronomical costs. In contrast, with offline intelligence, hardware costs are already covered, and ongoing use comes with almost no extra cost. From a business perspective, for massive device deployments, local deployment is the most cost-effective solution.
Local models are like smart butlers guarding your door—private, secure, and personalized to understand you. Even if they may not solve every complex problem, they should be able to handle 80% of daily tasks—opening apps, setting reminders, simple translations, generating meeting minutes, and more—and they do it so quickly and securely. For the vast majority of users, complex tasks aren't needed every moment of the day.
Cloud models can meet users' higher demands, but device-based models can serve most demands more quickly, securely, and cost-effectively.
02
What Should a Model Capable of Offline Inteligence Look Like?
Q: As mentioned earlier, in order to achieve offline intelligence, you chose the most challenging path—redesigning an "off-road vehicle." What exactly is the "engine" of this new vehicle, or the core mechanism of your new architecture?
Zou Jiasi: Our core innovation is abandoning the energy-intensive Attention mechanism of the Transformer architecture, which requires "global handshaking," and reverting to a lighter "feature-suppression-activation" architecture. Combined with section-wise activation, the model reduces the number of parameters actually computed to one-tenth or even lower, cutting computational power requirements to more than one-fifth of the original and power consumption to one-tenth. As mentioned earlier, in the standard Transformer architecture, regardless of how small the task is, all parameters must be fully activated to produce a high-intelligence output. However, the human brain does not operate this way.
The human brain has 80-90 billion neurons, which we can conceptualize as an 80-90 billion parameter model. If the human brain were to fully activate all parameters, its power consumption could reach 3,000 watts, or even 4,000 watts. However, the actual power consumption of the human brain is less than 30 watts.
How does the human brain achieve this remarkable feat? It does so through section-wise activation. Our model draws inspiration from this approach.
In addition to reduced power consumption, the new architecture also enables multimodal capabilities in a 3B model.
Using a somewhat informal analogy, when you see a bird, hear its call, and simultaneously read the word "bird," your brain is not fully activated all at once. Instead, it activates specific, small groups of neurons in distinct regions such as the visual cortex, auditory cortex, and language cortex. It is precisely this independent yet overlapping activation across these regions that allows us us to efficiently align visual, sound, and linguistic information.
Transformer models under 3 billion parameters struggle to efficiently process and align multimodal information due to their global computation characteristics. Our brain-inspired activation mechanism, however, more closely resembles the brain's section-wise processing model. Different modality inputs naturally activate distinct regions, making alignment easier and more precise. As a result, even at the 3B scale, we retain strong joint understanding capabilities across text, speech, and vision.

Q: The "section-wise activation" approach is indeed ingenious. However, the human brain can activate only a small part because it is a massive model with nearly 100 billion parameters, giving it a strong foundation. Our current edge models, on the other hand, have only tens of billions of parameters, which is like trying to fit a palace in a teacup. Can we really expect a small model to achieve better intelligence by activating an even smaller part?
Zou Jiasi: Your question touches on the core of the current large-model development paradigm—what we call the challenges of compressed intelligence.
Current pre-trained large models are essentially a process of compressing intelligence—like a massive sponge, their training process involves compressing vast amounts of internet data, which we can think of as water, into a container made up of several hundred billion parameters. The larger the number of parameters, the bigger the sponge, and the more knowledge it can absorb and store.
This paradigm faces certain challenges when handling multimodal data. Anyone familiar with file compression knows that a 1 GB text file, when compressed, is smaller than a 1 GB video or image file. Video and image files are naturally large and compress poorly. This is why Transformer models with fewer parameters struggle to incorporate multimodal capabilities.
Therefore, if the game is simply about who has the bigger sponge or the thicker book, small-parameter models indeed have no future.
However, we believe that true intelligence should not merely be about compression; it should be more about growth and learning. This is the fundamental difference in our approach: we are not sticking to a single path, but rather taking a dual-track approach of intelligence compression + autonomous learning.
The section-wise activation we mentioned earlier is significant not only for energy savings, but also because it allows growth.
Our current model has only 3 billion parameters. However, through fine-grained dynamic sectioning in the neural network—for example, dividing it into 100 sections—only 30 million parameters need to be activated at a time. This means that in the future, we could increase the total parameters of the edge model to 10 billion or even more, within the constraints of a mobile phone memory. Yet, by activating only a tiny fraction of these parameters, we can still maintain low power consumption.
This completely changes the game. We no longer focus on how to make large models smaller, but on how to enable models to grow from small to large on the edge.
So, while others are caught up in intense competition on compression, we have found a second—and in our view, more fundamental—growth trajectory for edge models through the MCSD architecture, section-wise activation, and memory units: a sustainable, low-cost, autonomous learning approach. We are not just building a model that can run on device; we are constructing a new, continuously growing brain foundation for the future of edge AI.
Q: You mentioned the term "autonomous learning." How should we understand the Yan model's autonomous learning capability? How does it differ from the personalization features of the current cloud-based models?
Zou Jiasi: Autonomous learning is one of the most exciting technological breakthroughs we aim to showcase at this year's WAIC.
Currently, the cloud-based large models we encounter require pre-training to update their intelligence. This is because the true learning process of a model—understanding users' feedback and reflecting it in changes in its neural network—relies on forward propagation (inference/guessing) and backward propagation (learning/correction). Backpropagation itself is highly energy-intensive. In the cloud, a 100-billion-parameter model performing a single backpropagation requires a massive training cluster composed of thousands of GPUs.
Therefore, once a Transformer-based model is deployed on your phone, it effectively becomes read-only. It can only perform forward propagation and loses the ability to learn and update. The so-called personalization we see is merely the model remembering some of your preferences through dialogue and storing them in an external knowledge base—it does not truly learn your preferences. As a result, even if you repeatedly emphasize your preferences to the model, the model can still produce outputs according to its own preferences.
Our innovation overcomes this fundamental physical limitation, achieving what seemed like an impossible breakthrough: it enables the backpropagation learning process to occur on edge devices for the first time.
Thanks to the traits of section-wise activation, when the model needs to learn new knowledge—such as remembering your preference for "coffee without sugar"—it does not need to alter the entire neural network with tens of billions of parameters. Our architecture can lock in the activated, tiny neural network section that is directly related to this new knowledge. Within this isolated micro-region, a low-power backpropagation updates only a few weight parameters in that section. This newly learned knowledge is then written directly and permanently into the model's neural network.
In this way, the door to personalized memory and autonomous learning is opened.
Now, our model can use (perform inference) and learn (train) simultaneously, directly integrating newly learned information—such as your new habits or preferences—into the model's core. This grants the model true autonomous learning capabilities.

03
When Will Offline Intelligence Reach AI Toys?
Q: We’ve discussed many technical impossibilities and possibilities. Now let’s return to the market. While most voices are still chasing after a 100-billion-parameter model in the cloud, your technology has quickly secured real commercial orders. This makes us very curious. From your perspective, which type of players in the current market shows the strongest interest in offline intelligence? What are the underlying commercial drivers behind them?
Zou Jiasi: Currently, we have engaged with clients across multiple industries, and behind each client’s interest in offline intelligence lies a profound commercial logic.
PCs, tablets, and robots are our current core focus areas where we have achieved mass production. We are particularly focused on the broader mid-to-low-end computing power market.
Take our collaboration with a leading overseas manufacturer as an example. Their core objective is not merely to develop AI features for future flagship models but also to revitalize the hundreds of millions of mid-to-low-end devices they have already sold or are currently selling.
Why do hardware manufacturers care so much about these older devices? There are two key reasons:
The first is for devices already in users' hands. By pushing our AI models to these older devices via OTA (Over-The-Air updates), we can generate new revenue from pre-installed software and value-added services. More importantly, this significantly enhances brand value—"The computer I bought years ago can now be upgraded to an AI PC!" Such word-of-mouth is priceless.
The second is for non-flagship models currently in production. No brand can survive solely on high-end AI PCs priced in the tens of thousands. True sales and profits come from the vast mid-to-low-end market. However, these devices, due to chip computing power limitations, cannot run mainstream Transformer models, yet manufacturers do not want their products to be AI-incompatible.
Our technology is precisely the solution to this gap. Our models can run smoothly on these non-flagship devices, allowing manufacturers to deliver AI PCs to users next month, rather than waiting for three years.
In addition to PCs and tablets, we also focus on robotics and mobile phones. We have some collaboration with drone companies as well.

Q: What about the trending fields of AI glasses and AI toys?
Zou Jiasi: These two categories are nearly always the first questions that media and investors ask us when they meet us. They represent the most exciting possibilities of on-device AI, but they also reveal the stark reality.
The fundamental issue is actually the same: to achieve extreme cost control and portability, the chips in these devices were not designed to run AI from the outset.
Take AI glasses as an example. The mainstream solutions currently available on the market use either Qualcomm's AR-specific chips or chips from manufacturers like Bestechnic. These chips are essentially communication chips, designed for tasks such as Bluetooth connectivity, screen mirroring, and simple translation. Their computational power is strictly limited.
As a result, our models cannot run on most glasses, as the computational power and memory of these devices are completely inadequate. Even we can't run our model on them, let alone Transformer models with tens of billions of parameters—that would be utterly unrealistic. AI toys face the exact same challenge.
The market has extremely high unrealistic expectations for the user experience, but the physical reality of hardware is extremely stark.
Faced with this deadlock, we currently see two clear paths forward, both of which we are pursuing simultaneously:
The first path is an "roundabout solution," which is also the most pragmatic option at present. Since the glasses themselves lack sufficient computing power, we will leverage the computing power of smartphones. We are currently engaged in in-depth discussions with leading eyewear manufacturers regarding this solution.
The other path is a more radical, future-oriented approach that addresses the root cause. We are collaborating with bold partners like INMO to explore a daring idea: directly replacing the current processor with a more powerful "brain chip" in the next-generation glasses.
This will undoubtedly present significant challenges in terms of power consumption and industrial design. However, if successful, it would result in a truly unique pair of glasses capable of achieving real offline intelligence. Imagine wearing it while traveling abroad and achieving instant, high-quality offline translation in an environment without any network connection—this experience would be mind-blowing and provide a clear differentiated advantage.
Therefore, for the eyewear and toy markets, we have both pragmatic "current solutions" and forward-looking "ultimate solutions." We are very patient because we believe that true breakthroughs require the perfect synergy of technology and hardware.
Q: The AI hardware sector in China is currently very trending, but it primarily relies on cloud-based AI. However, I’ve noticed that your customers' target are overseas. Is there a difference in market demand between China and overseas markets when it comes to offline intelligence?
Zou Jiasi: The gap in market enthusiasm that you observed is actually at the core of our current strategy. Smart hardware sold to overseas markets offers us a much larger untapped opportunity. This strong demand is mainly driven by three "pain points" that are less noticeable in the domestic market.
First, the culturally ingrained value of privacy. In Western markets, users' concern for personal data privacy is enshrined in law and deeply ingrained in society. We are currently in discussions with a leading toy IP company about a partnership. One of the core prerequisites for their interest in our solution is that they do not want user privacy data to be stored in the cloud. Their content IP and user data are their most valuable assets and must be processed on the device itself.
Second, there is an existing gap in internet access. We are easily accustomed to ubiquitous 5G networks in China's first-tier cities, assuming that connectivity is guaranteed. However, on a global scale, our overseas partners's users may be in remote areas of Africa or islands in Southeast Asia, where network conditions make cloud-dependent AI experiences highly unreliable. An offline model capable of running stably in weak or no-network environments is their lifeline.
Third, the demand for efficiency driven by higher labor costs. In many overseas scenarios, there is greater readiness to use machines in place of human labor. When a reliable, offline 24/7 receptionist or multilingual guide is needed, the commercial value of offline intelligence becomes more immediate and acutely apparent than in the domestic market.
Therefore, our strategy is very clear, and we call it "sailing overseas on a borrowed boat." Through this approach, we enable top Chinese companies expanding overseas to bring our technology to global end-users with the strongest and most urgent demand for offline intelligence.
Q: Your insights paint an exciting future, but they also highlight a sharp reality: on one hand, edge models are a key focus for all smart hardware manufacturers, with both domestic and international smartphone giants investing heavily in R&D to master the core of AI capabilities; on the other hand, Moore's Law for hardware is advancing rapidly. In two or three years, when smartphone chips become powerful enough to easily run larger models, will your current "small yet sophisticated" advantage still hold? Facing such a future, what is RockAI's deepest moat?
Zou Jiasi: Your question is very pointed, and it highlights precisely the two core challenges we consider every day.
First, regarding hardware becoming more powerful. We believe this is a trend that works in our favor. First, the widespread adoption of any high-end hardware requires at least a two- to three-year window. During this window, we are the optimal solution for bringing AI capabilities to large volumes of existing and mid-range devices. Second, as the hardware foundation becomes more powerful, it can accommodate not only larger Transformers but also our Yan architecture large models, which we have developed from the ground up. We can also build 10B or even larger models, and our unique advantages, such as autonomous learning and low power consumption, will still exist.
The other question may go to the very heart of our company, revealing what our true moat is.
Our team's DNA actually stems from an unfulfilled dream that began in 2015. At that time, we founders wanted to create true smart hardware, similar in concept to Xiao Ai, but the project failed due to the immaturity of AI technology at the time. It wasn't until we saw the potential of Transformers that we felt the time was right to come together again and start a business.
Later, we painfully realized that forcing the Transformer, this "cloud-based powerhouse," into a small device was simply not feasible from an engineering standpoint.
At that point, we faced two paths: one was to follow the industry mainstream, patching the Transformer and making various optimizations—a path that was easier and more understandable to investors. The other was to take a more difficult and solitary path, admitting that the first path was unfeasible, and starting from scratch to build a brand-new architecture designed specifically for edge devices.
We chose the latter. What sustained us wasn’t how much money or resources we had, nor how impressive our team’s background was. Internally, we summed it up with a rather intangible word: perseverance.
We firmly believe that models must run on the edge, and devices must have their own intelligence. It was precisely because of this unwavering conviction that we were willing to sit on the sidelines for over two years, while others chased the cloud computing trend. We acted like experimental alchemists in a laboratory, repeatedly experimenting and validating, until we finally refined the Yan architecture large model.
Therefore, our moat is not based on one or two technical points, as there are too many smart people and teams out there. Our moat is the knowledge we have accumulated through the challenges we have overcome due to our persistence, as well as the innovative DNA we have had since day one, which is uniquely tailored for edge intelligence.
推荐新闻
-


Harnessing Collective Intelligence Instead of Creating Gods: This Company Takes a Unique AGI Path Different from OpenAI
-

LLM Architecture Design and Algorithm Optimization for Edge AI
-

RockAI Participated in the Hong Kong EFAE with Its Partner, Where Autonomous Learning and AIPC Attracted Great Attention!
-
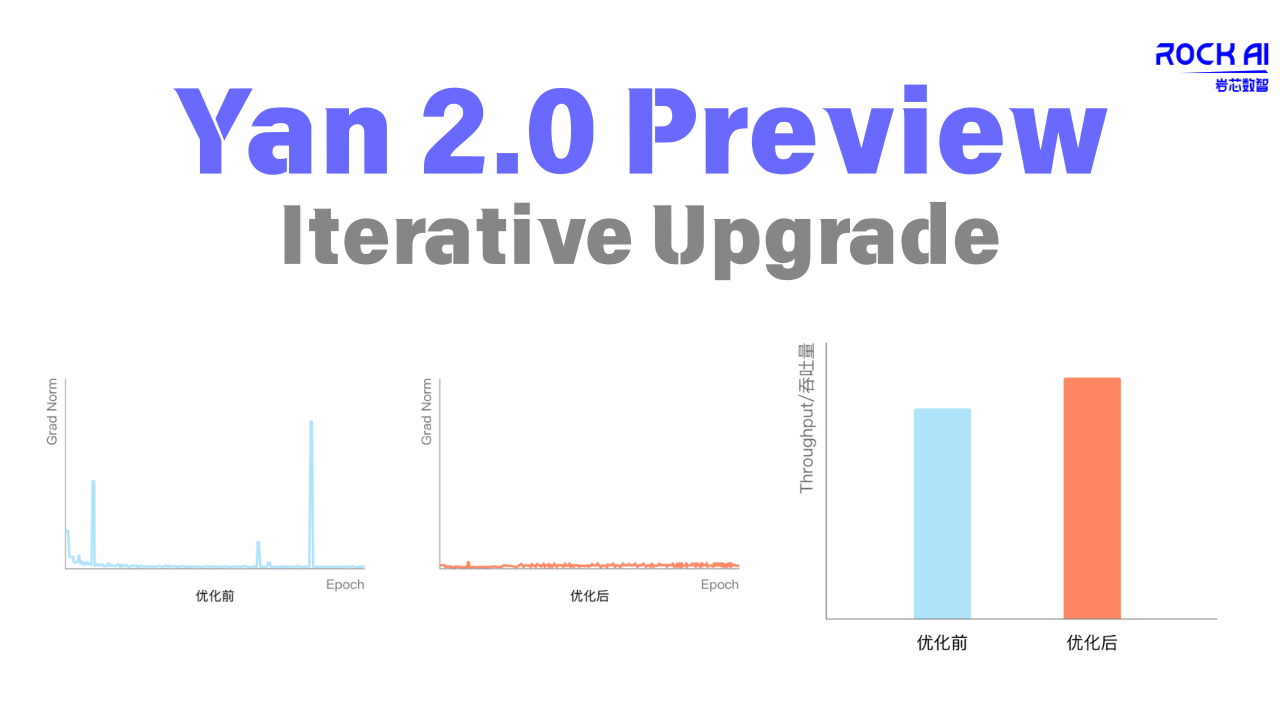
Yan 2.0 Preview Iterative Upgrade: More Stable Training, Faster Inference









