

Technical Insights
2025年08月08日
World’s First AI Model with "Native Memory" Debuts at WAIC—and It’s Not Transformer-Based
分享
Original article by Zhang Qian | 机器之心 Jiqizhixin
Published on July 26, 2025, 17:32 | Sichuan
Eight years after the introduction and domination of the Transformer in the large-model landscape, its creator Google is now showing early signs of striking out in a new direction.
Last month, Google's product lead Logan Kilpatrick highlighted the limitations of the current attention mechanism. Shortly after, Google introduced a new architecture called MoR. These moves indicate that "architectural innovation" has become a widely shared consensus in the AI field.
At the recently opened WAIC (World Artificial Intelligence Conference), we also observed this trend. In fact, the approaches taken by domestic companies appear even more sweeping than Google's transformation.
The robotic hand in the video is powered by an offline multimodal large model. Although the model is only 3B in size, once deployed on-device, its conversation quality and latency are nearly comparable to much larger models running in the cloud. It also possesses multimodal capabilities such as "seeing, listening, and thinking."

An important point is that it is not based on the Transformer architecture, but rather on Yan 2.0 Preview, a non-Transformer architecture proposed by a Chinese AI startup RockAI. This architecture significantly reduces the computational complexity during model inference, enabling offline operation on devices with very limited computing power, such as the Raspberry Pi.
Moreover, unlike other "small-parameter versions of cloud-based large models" running on devices, this model possesses a certain degree of native memory, allowing it to perform inference while integrating memory into its own parameters.
In other words, when chatting with other large models, each time you open a new conversation window, the model doesn't remember what you talked about previously. It is like a friend who forgets you every time they wake up—you meet them every day, yet each encounter always feels like "the first." In contrast, the model built based on Yan architecture can gradually get to know you better over time, and respond to each of your questions based on that accumulated understanding. This is something most Transformer-based cloud models are still unable to achieve—let alone "small models" whose learning capabilities has been compromised by techniques like pruning and distillation.
Why does RockAI make such sweeping changes to the Transformer? How are these changes accomplished? What is their significance for the realization of AGI? After an in-depth conversation with RockAI's founding team, we gained valuable insights.
Transformers Have Been Trending for Years, So Why Is RockAI Starting from Scratch?
RockAI's challenge to the Transformer didn't start this year. In fact, as early as January 2024, they launched version 1.0 of the Yan architecture—after spending two years exploring architectural innovation.
It is well known that Transformer architectures face challenges such as "data silos" and "compute dependency." On one hand, current large models rely on massive amounts of data for pretraining, but as high-value data becomes increasingly difficult to obtain, this approach is becoming harder to pursue. On the other hand, Transformer model inference demands extremely high computational power. Without techniques like quantization and pruning, it is difficult to deploy these models directly on low-power devices. Moreover, even if deployment is possible, it is hard for such models to undergo major updates, as the computational load required for backpropagation cannot be supported by ordinary devices. Achieving "training and inference synchronization"—that is, allowing the model to learn and update its parameters while performing inference, much like how a child learns from an adult during interaction—is difficult to realize. Furthermore, operations such as quantization and pruning further degrade the model's learning ability.
As a result, Transformer models that run on device becomes a "static" model, with its intelligence level locked at the time of deployment.
To fundamentally address these issues, RockAI took a sweeping transformation path from the outset, exploring the Yan architecture—a non-Transformer, non-Attention mechanism—from scratch. What's even more impressive is that they not only quickly identified an effective technical path but also successfully achieved commercial deployment on devices with limited computational power.

Yan 2.0 Preview: World's First Large Model with "Native Memory"
The figure below shows the comparison results of Yan 2.0 Preview with other architectures in terms of performance and effectiveness. It can be seen that Yan 2.0 Preview has solid advantages over both mainstream models based on the Transformer architecture and next-generation models based on non-Transformer architectures in terms of multiple key metrics such as generation, understanding, and inference. This fully demonstrates the significant advantage of Yan architecture in terms of the "performance/parameter" ratio (i.e., efficiency).
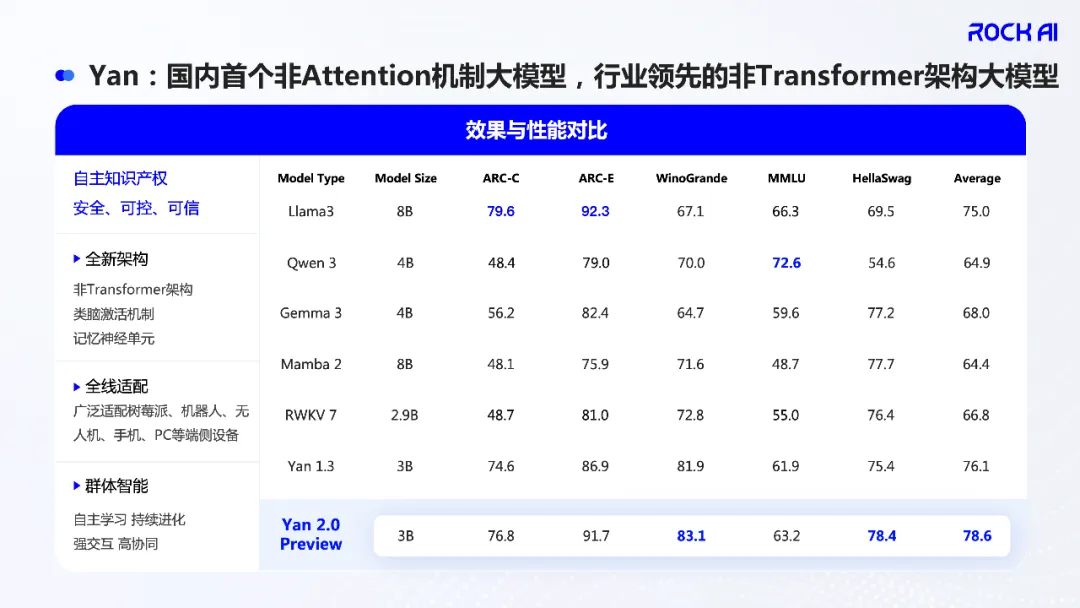
Of course, this is not the main highlight, as in Yan 1.3, we have already seen its impressive computing efficiency. The highlight this time is "memory."
We observed that, whether in recent papers, new products, or public discussions, "memory" is becoming a central focus. It is viewed both as a critical shortcoming of current LLMs and as the next breakthrough point for the commercial application of AI. Imagine a Labubu that can talk and has exclusive memories shared between you. After spending many years together, wouldn't your emotional bond with it grow deeper?
However, in terms of technical approaches, the industry currently relies primarily on "external add-ons" (such as long-context stacking with search engines or RAG) to extend memory in large models. RockAI is not optimistic about this approach. This is because, first, it processes information as a linear sequence, lacking a true concept of "time" (this is essential for real learning that evolves over time), which is fundamentally different from how human memory works. Second, it fails to achieve true personalization.
"Looking back at human society, each individual possesses unique memories. The differences between humans stem from their distinct memories and experience. These differences ultimately shape the diversity of human society, shaping our respective behaviors and styles of expression. Currently, the commercial models we use are essentially the same cloud-based model, lacking true personalization, and they can only provide context through retrieving past chat records. This approach has clear limitations, for instance, when it comes to writing, the model is unable to generate content tailored to a user's personal style.", pointed out Liu Fanping, CEO of RockAI.
He believes that only by integrating native memory capabilites into the model can this situation be changed. Therefore, they chose a different approach in Yan 2.0 Preview—internalizing the model's understood information into the neural network's weights, making it a part of the model itself. This approach more closely resembles how memory works in biological systems.
The sketch map below illustrates the architecture of Yan 2.0 Preview. It enables memory storage, retrieval, and forgetting through a differentiable "neural memory unit."
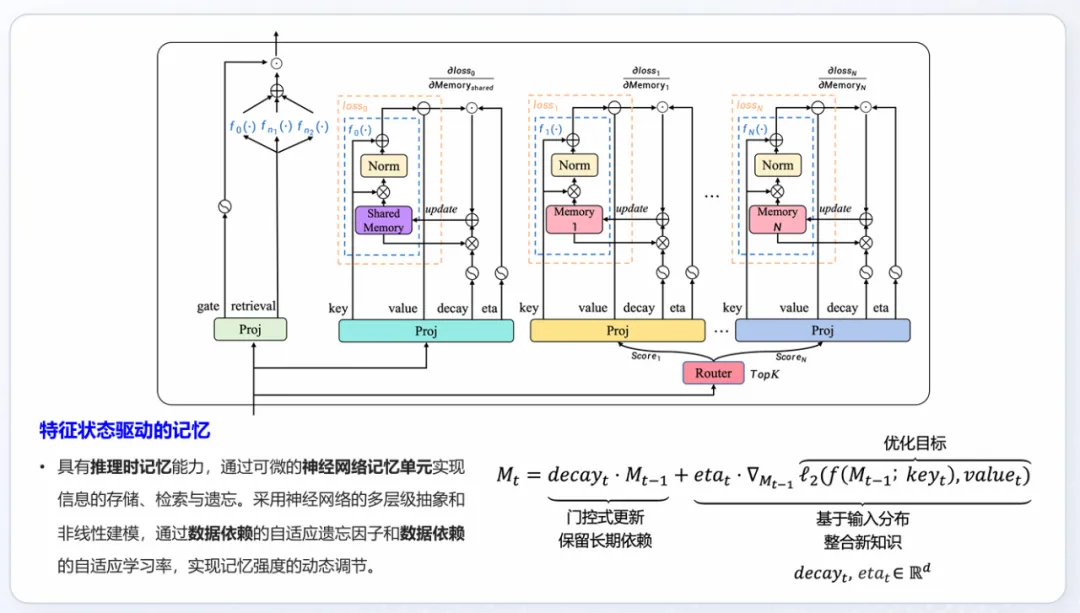
In principle, this mechanism is similar to the evolution of artificial intelligence from early machine learning to deep learning. In the early days, machine learning required manually designed or extracted features. While this approach offered high interpretability, it also involved heavy customization and strong reliance on expert experience. Deep learning, on the other hand, allows for automatic feature extraction. By designing neural networks, setting optimization goals and strategies, and traning on large data corpora, it enables end-to-end learning. Similar to this, Yan 2.0 Preview has achieved end-to-end memory, eliminating the need for users to manually manage the external knowledge bases (such as adding, deleting, modifying, or retreiving information), making it much more convenient to use.
On-site, we experienced the native memory capabilities of Yan 2.0 Preview through a robotic dog that could "learn and perform on the spot." Even after "reopening the chat window," the robotic dog was still able to remember the actions and preferences that it had previously learned.
When memory becomes deeply integrated into the model architecture, it no longer functions as a temporary "cache," but rather as a form of "intelligent accumulation" that encompasses time dimension, personalization, interaction context. Once mature, it may reshape the current learning paradigm where large models depend heavily on massive datasets.
The role of the model will also evolve—from being a mere respondent to gradually becoming an extension of the user's thinking and decision-making, truly enabling "long-term companionship and personalized services." When this capability is deployed on local terminals, and combined with the advantages of on-device privacy protection and real-time responsiveness, the device transforms from a passive tool into a "digital brain" with the ability to perceive, remember, and learn.
Offline Intelligence: Make Every Device Its Own Intelligence
Every researcher who has attempted to challenge the Transformer knows just how difficult it is. According to Yang Hua, the CTO of RockAI, the reason RockAI has persevered to this day lies in three core principles the team has upheld over the years:
First, they believe that AI should be accesible and beneficial to everyone, and therefore should not exist solely in the cloud. AI must interact with the physical world to realize its full potential, which requires it to be deployed on devices. This has become an industry consensus and is also one of the reasons why fields such as embodied intelligence and spatial intelligence have become so popular.
Second, in the long term, a truly intelligent device should not be static but it should be capable of growth and evolution. Possessing learning capabilities ensures that "individual" intelligence is sufficiently smart. This idea has also been reflected in the recent industry discussions about "self-evolving AI". However, RockAI emphasizes that self-evolution should occur within "individual" devices rather than in cloud-based large models.
Third, once the "individual" devices become sufficiently intelligent, the network formed by these devices is expected to give rise to collective intelligence—much like how human society has already created such a brilliant civilization. RockAI believes that collective intelligence is a key pathway toward achieving Artificial General Intelligence (AGI).
These principles have been put into practice, shaping RockAI's core mission: "Make Every Device Its Own Intelligence."
This mission may sound similar to "edge intelligence." However, Yang Hua emphasized that what they are actually pursuing is "offline intelligence"—relying solely on the computational power of local devices, unlike many "edge-cloud hybrid" architectures that require an internet connection. Moreover, in this offline mode, models can learn autonomously, rather than having a fixed intelligence at the time of deployment. A model with autonomous learning capability can be seen as a child with learning potential. While it may not be as capable as a 30-year-old PhD when it first steps out into the world, it will grow stronger over time.
Do not underestimate the value of this kind of "growth"—in the future, it may be the key differentiator in competition among devices. Liu Fanping mentioned, when we buy hardware nowadays, we mainly look at the specs; it's a one-time deal, and its value begins to depreciate as soon as it's in our hands. But with memory and autonomous learning capabilities, the long-term value of hardware begins to emerge. The degree of intelligence and its ability to evolve will become the hardware's new selling points.
Moreover, this kind of "growth" also makes the emergence of collective intelligence possible—only when every device is equipped with autonomous learning capabilities can they truly achieve shared knowledge, collaborative evolution, and ultimately give rise to collective intelligence that goes beyond the simple sum of individiual intelligences. This is also RockAI's ultimate vision.
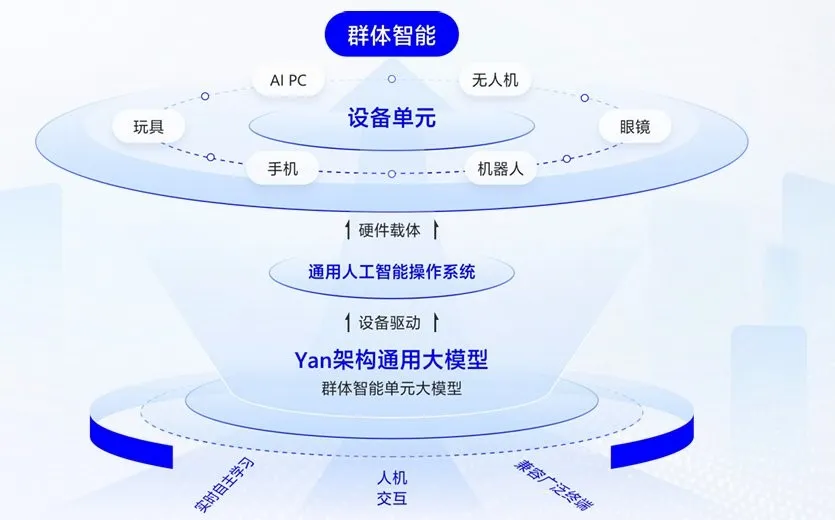
From "Skepticism" to "Consensus": RockAI Has Always Tackled What is "Difficult but Right"
Looking back over several years of research and development, RockAI has clearly sensed a shift in external attitudes toward their chosen technology path.
A few years ago, when RockAI spoke of developing collective intelligence and building a new architecture from scratch, people were mainly curious, puzzled, and skeptical, since this didn't seem like something a start-up should be doing.
But this time, with the unveiling of native memory capabilities, people began to understand what makes RockAI's approach distinct. Their work goes beyond simple model training or parameter stacking. While persisting in tackling in the techincal path of what is "difficult but right", with "memory" as its core, they are redefining the boudaries of large model capabilities, offering an outstanding user experience.
Zou Jiasi, the CMO of RockAI said that their choice of technical path made them stand out across the entire WAIC exhibition. Many hardware manufacturers with demands for on-edge deployment and memory capabilities approached them to learn more about their technical solution. These manufacturers had also experimented with Transformer-based models, however the experience didn't meet their requirements. In addition, there are several manufacturers that have already established cooperations with RockAI. The non-Transformer Yan architecture is now spreading across the AI hardware market.

It must be acknowledged that the decision made by RockAI a few years ago was highly foresighted. It has also responded to external skepticism with both scientific research and commercial achievements.
Yang Hua stated that in the future, they will continue to pursue what is "difficult but right." In order to achieve more efficient autonomous learning capabilities, they are continuously challenging the foundation of artificial intelligence—the backpropagation algorithm. Their current solution has already completed performance evaluation and traning convergence verification on small-scale data, demonstrating the basic feasibility of their approach.
Amongst many AI startups, such foresight and the resilience to stick to one's own path are rare, very similar to the path taken by frontier labs like OpenAI. After all, back when Ilya was busy scaling up, the scaling law had not yet become widely accepted. From RockAI, we see a commendable spirit of "long-termism"—a willingness to spend years tackling fundamental technical challenges and validating technical ideas that once seemed "unrealistic," even amid the restless startup environment.
Innovation is a lonely journey. We look forward to RockAI and more explorers going even further down this path.
推荐新闻
-


Harnessing Collective Intelligence Instead of Creating Gods: This Company Takes a Unique AGI Path Different from OpenAI
-

LLM Architecture Design and Algorithm Optimization for Edge AI
-

RockAI Participated in the Hong Kong EFAE with Its Partner, Where Autonomous Learning and AIPC Attracted Great Attention!
-
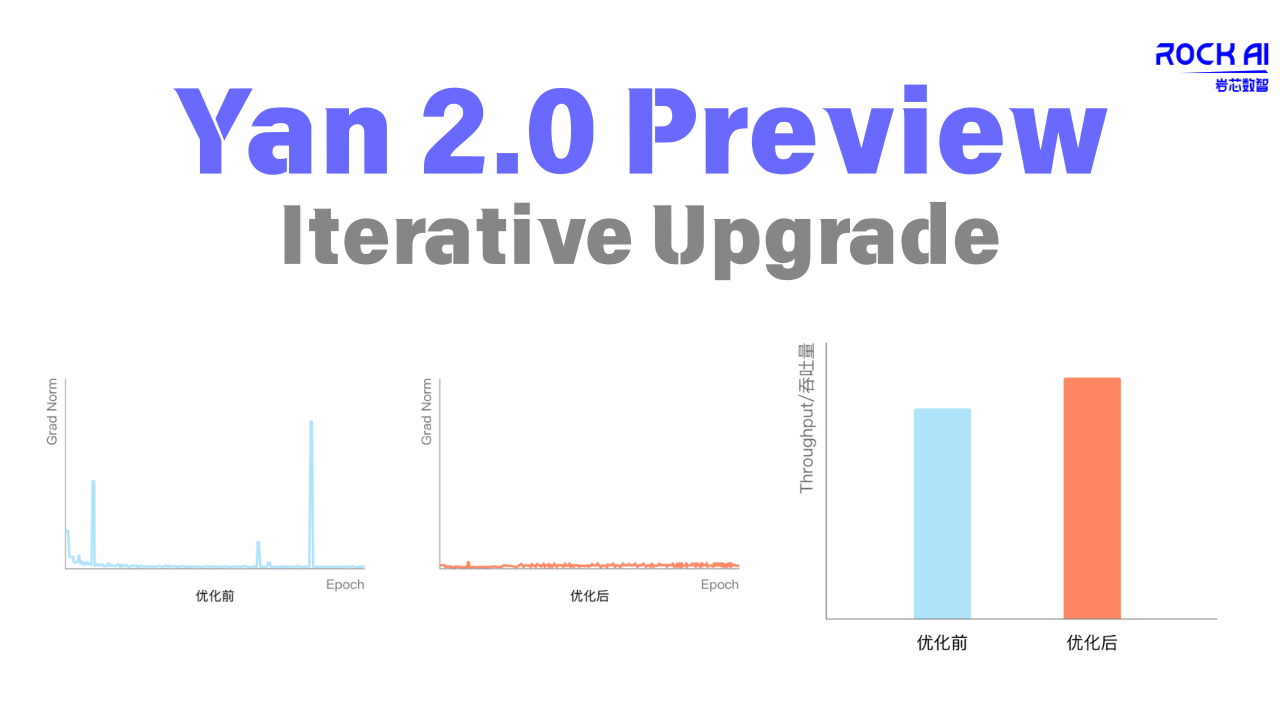
Yan 2.0 Preview Iterative Upgrade: More Stable Training, Faster Inference









